Hugging Face Autotrain
🤗 AutoTrain は、自然言語処理 (NLP) タスク、コンピュータビジョン (CV) タスク、音声タスク、さらには表形式データタスクのために最先端のモデルをトレーニングするためのノーコードツールです。
Weights & Biases は 🤗 AutoTrain に直接統合されており、実験管理と設定管理を提供します。実験のためのCLIコマンドで1つのパラメーターを使用するだけで簡単に利用できます!
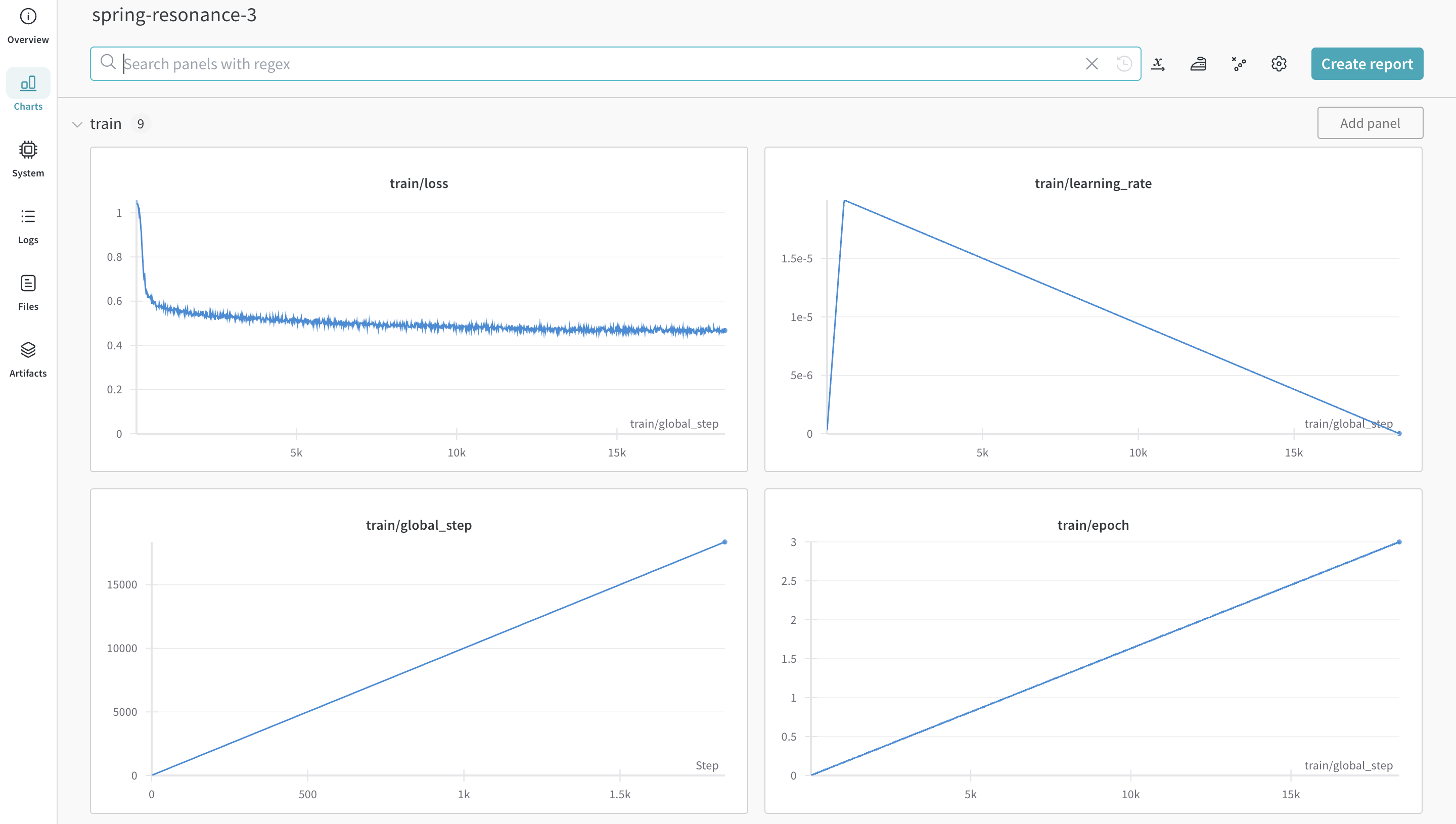 |
|---|
| 実験のメトリクスがどのようにログされるかの例。 |
はじめに
まず、autotrain-advanced と wandb をインストールする必要があります。
- Command Line
- Notebook
pip install --upgrade autotrain-advanced wandb
!pip install --upgrade autotrain-advanced wandb
はじめに: LLMのファインチューニング
これらの変更を示すために、数学データセットでLLMをファインチューンし、GSM8kベンチマーク でpass@1のSoTA結果を達成しようと試みます。
データセットの準備
🤗 AutoTrainは、CSV形式のカスタムデータセットを適切な形式で動作させることを期待しています。トレーニングファイルには、トレーニングが実施される「text」列が含まれている必要があります。最良の結果を得るために、「text」列には ### Human: Question?### Assistant: Answer. フォーマットでデータが含まれている必要があります。AutoTrain Advancedが期待するデータセットの優れた例は、timdettmers/openassistant-guanaco です。しかし、MetaMathQAデータセット を見ると、「query」、「response」と「type」の3つの列があります。このデータセットを前処理して「type」列を削除し、「query」と「response」列の内容を### Human: Query?### Assistant: Response. フォーマットで「text」列にまとめます。結果として得られるデータセットはrishiraj/guanaco-style-metamath であり、トレーニングに使用されます。
Autotrain Advancedを使用したトレーニング
Autotrain AdvancedのCLIを使ってトレーニングを開始できます。ログ機能を活用するためには、単に--log 引数を使用します。--log wandb を指定すると、結果がシームレスに W&B run にログされます。
- Command Line
- Notebook
autotrain llm \
--train \
--model HuggingFaceH4/zephyr-7b-alpha \
--project-name zephyr-math \
--log wandb \
--data-path data/ \
--text-column text \
--lr 2e-5 \
--batch-size 4 \
--epochs 3 \
--block-size 1024 \
--warmup-ratio 0.03 \
--lora-r 16 \
--lora-alpha 32 \
--lora-dropout 0.05 \
--weight-decay 0.0 \
--gradient-accumulation 4 \
--logging_steps 10 \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token <huggingface-token> \
--repo-id <huggingface-repository-address>
# ハイパーパラメーターの設定
learning_rate = 2e-5
num_epochs = 3
batch_size = 4
block_size = 1024
trainer = "sft"
warmup_ratio = 0.03
weight_decay = 0.
gradient_accumulation = 4
lora_r = 16
lora_alpha = 32
lora_dropout = 0.05
logging_steps = 10
# トレーニングの実行
!autotrain llm \
--train \
--model "HuggingFaceH4/zephyr-7b-alpha" \
--project-name "zephyr-math" \
--log "wandb" \
--data-path data/ \
--text-column text \
--lr str(learning_rate) \
--batch-size str(batch_size) \
--epochs str(num_epochs) \
--block-size str(block_size) \
--warmup-ratio str(warmup_ratio) \
--lora-r str(lora_r) \
--lora-alpha str(lora_alpha) \
--lora-dropout str(lora_dropout) \
--weight-decay str(weight_decay) \
--gradient-accumulation str(gradient_accumulation) \
--logging-steps str(logging_steps) \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token str(hf_token) \
--repo-id "rishiraj/zephyr-math"
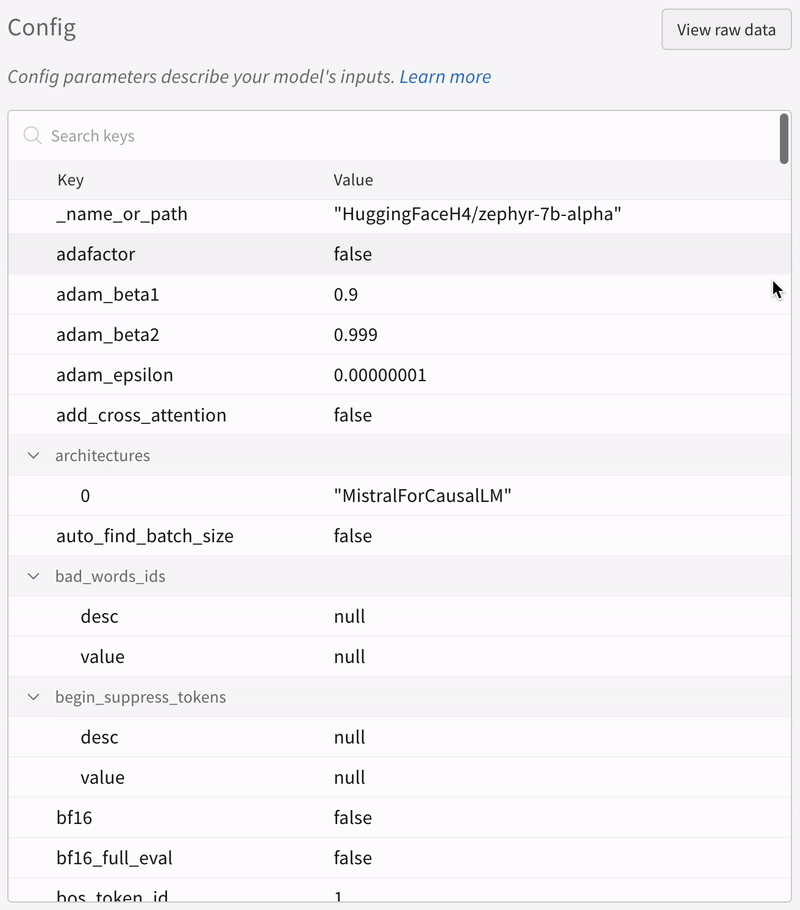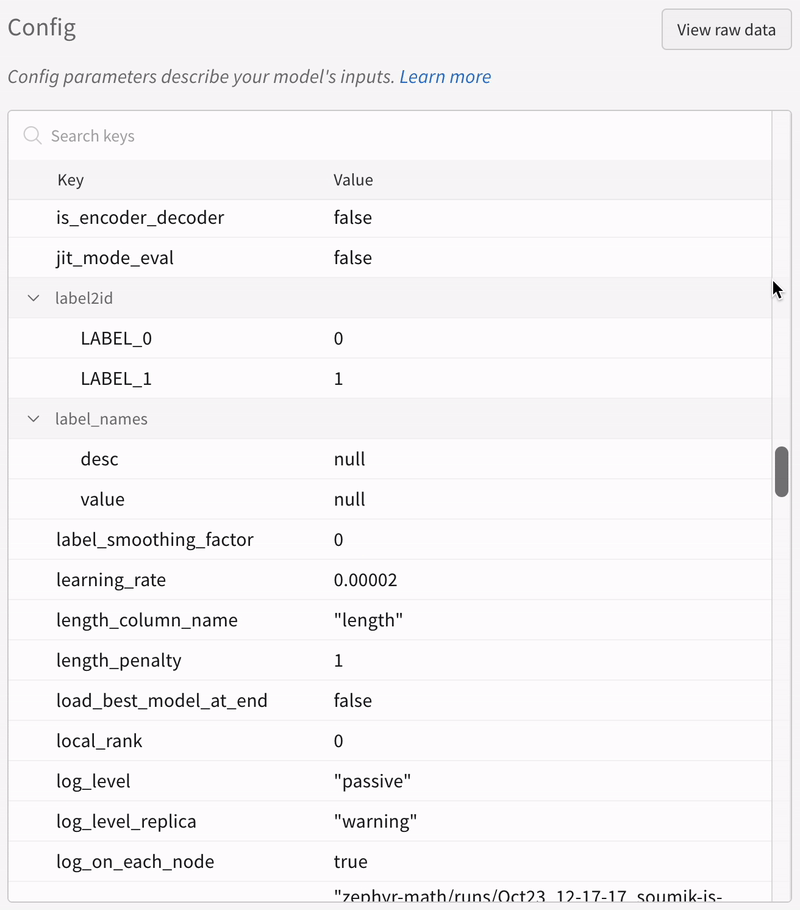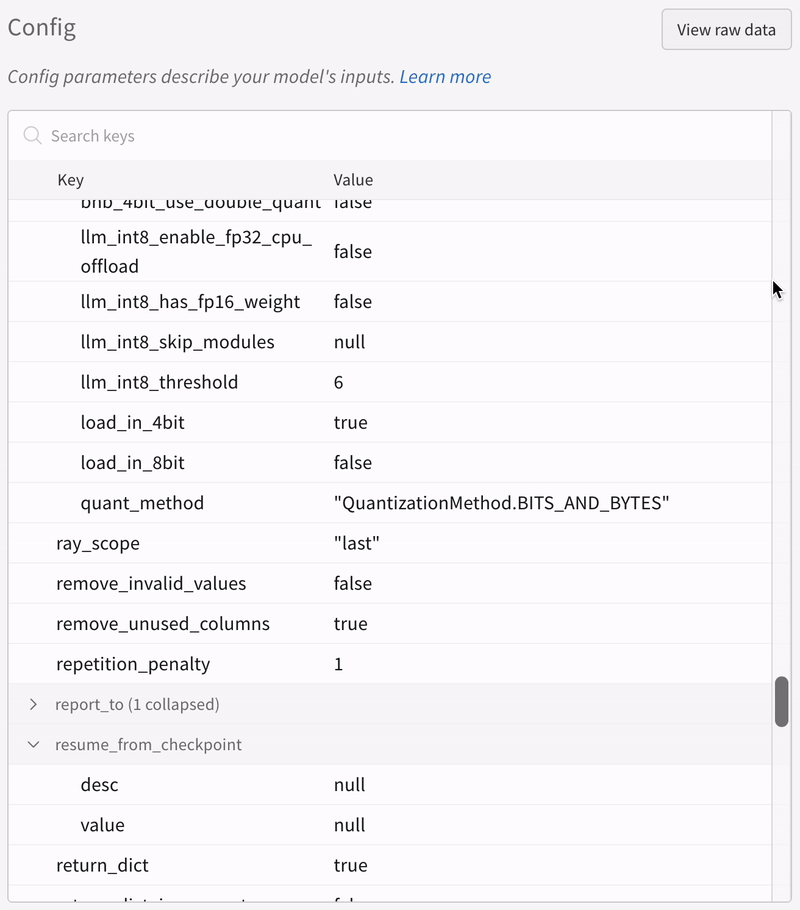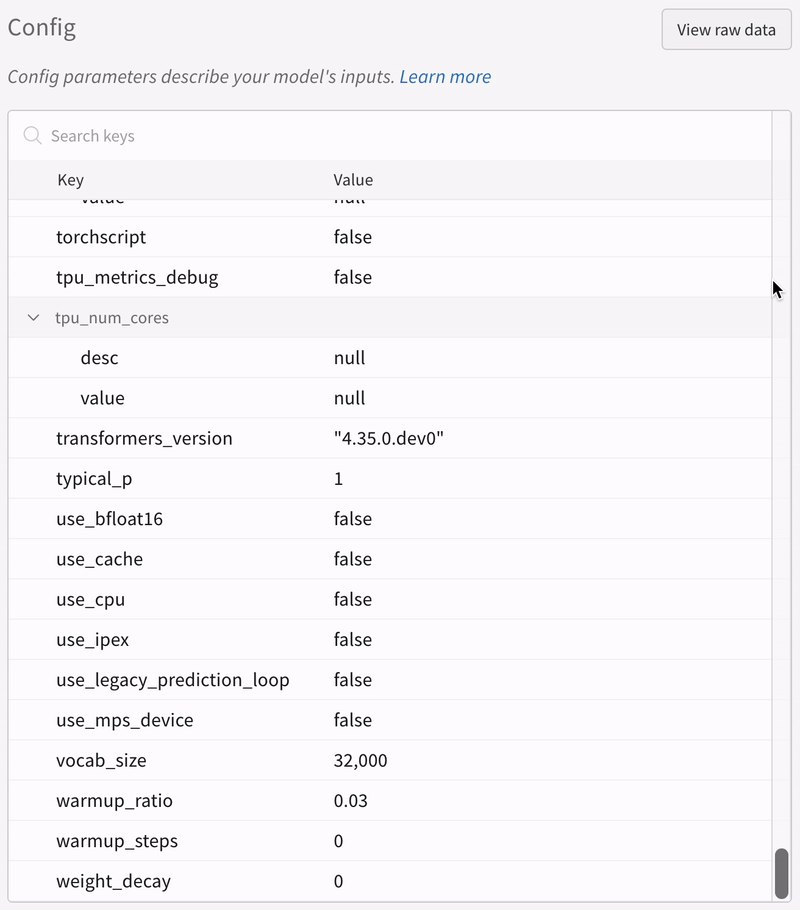 |
|---|
| 実験のすべての設定がどのように保存されるかの例。 |