Spin up a single node GPU cluster with Minikube
MinikubeクラスターでGPUワークロードをスケジュールし実行するためのW&B Launchのセットアップ方法。
このチュートリアルは複数GPUを搭載したマシンに直接アクセスできるユーザーを対象としています。このチュートリアルはクラウドマシンをレンタルするユーザー向けではありません。
クラウドマシンにMinikubeクラスターをセットアップしたい場合、W&Bはクラウドプロバイダ(AWS、GCP、Azure、Coreweave など)の提供するGPUサポート付きKubernetesクラスター作成ツールを使用することを推奨します。
1台のGPUを搭載したマシンでGPUをスケジュールするためにMinikubeクラスターをセットアップしたい場合、W&BはLaunch Docker queueを使用することを推奨します。このチュートリアルを参考にしても楽しいですが、GPUのスケジューリングはあまり役に立たないでしょう。
背景
Nvidia container toolkitにより、Docker上でGPU対応のワークフローを実行することが簡単になりました。制限の一つは、ボリュームによるGPUのスケジューリングのネイティブサポートがないことです。docker run コマンドでGPUを使用する場合、特定のGPUをIDで指定するか、全てのGPUを指定する必要があり、多くの分散GPU対応ワークロードが実用的ではありません。Kubernetes はボリュームリクエストによるスケジューリングをサポートしていますが、GPUスケジューリングを持つローカルKubernetesクラスターのセットアップには多くの時間と労力がかかります。しかし最近、人気のある単一ノードのKubernetesクラスターを実行するためのツールの一つ、Minikube がGPUスケジューリングをサポートしました 🎉 このチュートリアルでは、複数GPUを搭載したマシンにMinikubeクラスターを作成し、W&B Launch を使用してクラスターに同時実行の安定拡散推論ジョブを送信します 🚀
前提条件
開始する前に以下が必要です:
- W&Bアカウント。
- 以下の要件を満たすLinuxマシン:
- Dockerランタイム
- 使用したいGPUのドライバ
- Nvidia container toolkit
このチュートリアルをテストして作成するために、4つのNVIDIA Tesla T4 GPUが接続されたn1-standard-16のGoogle Cloud Compute Engineインスタンスを使用しました。
ジョブのキューを作成する
まず、Launchジョブのためのキューを作成します。
- wandb.ai/launch(またはプライベートW&Bサーバーを使用している場合は
<your-wandb-url>/launch)に移動します。 - 画面の右上にある青色のCreate a queueボタンをクリックします。右側からキュー作成ドロワーがスライドアウトします。
- エンティティを選択し、名前を入力し、キューのタイプとしてKubernetesを選択します。
- ドロワーのConfigセクションに「Kubernetesジョブ仕様」を入力します。このキューから起動されたすべてのRuns はこのジョブ仕様で作成されるため、ジョブをカスタマイズするために必要に応じて設定を変更できます。このチュートリアルでは、下記のサンプル構成をYAMLまたはJSON形式でキュー設定にコピー&ペーストしてください:
- YAML
- JSON
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: '{{gpus}}'
restartPolicy: Never
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
}
}
}
],
"restartPolicy": "Never"
}
},
"backoffLimit": 0
}
}
キュー設定に関する詳細情報については、Set up Launch on Kubernetes や Advanced queue setup guide を参照してください。
${image_uri} と {{gpus}} はそれぞれキュー設定で使用できる2種類の変数テンプレートの例です。${image_uri} テンプレートは、エージェントが起動するジョブのイメージURIで置き換えられます。{{gpus}} テンプレートは、ジョブを提出する際にLaunch UI、CLI、またはSDKからオーバーライドできるテンプレート変数を作成するのに使用されます。これらの値はジョブ仕様に挿入され、ジョブで使用されるイメージとGPUリソースを制御する正しいフィールドが変更されるようになります。
- Parse configuration ボタンをクリックして、
gpusテンプレート変数をカスタマイズします。 - Typeを
Integerに設定し、Default、Min、およびMaxを適宜設定します。このテンプレート変数の制約を違反するキューへのRunの提出は拒否されます。
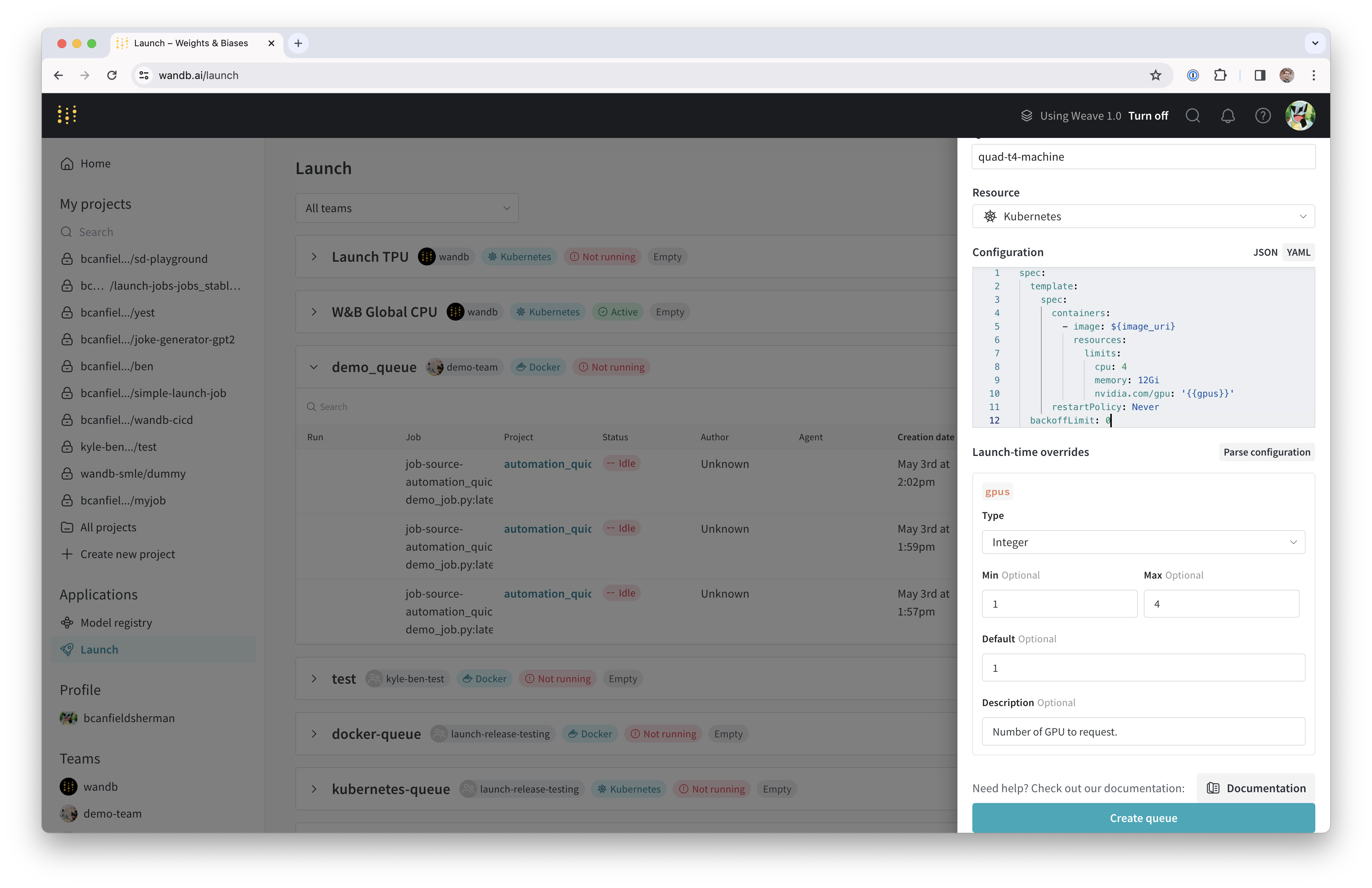
- Create queueをクリックしてキューを作成します。新しいキューのキューページにリダイレクトされます。
次のセクションでは、作成したキューからジョブを取得し実行するエージェントをセットアップします。
Docker + NVIDIA CTKのセットアップ
既にマシンにDockerとNvidia container toolkitがセットアップされている場合は、このセクションをスキップできます。
Dockerのドキュメント を参照して、システムにDockerコンテナエンジンをセットアップする手順を確認してください。
Dockerをインストールしたら、 Nvidiaのドキュメントの指示に従ってNvidia container toolkitをインストールしてください。
コンテナランタイムがGPUにアクセスできることを確認するため、次のコマンドを実行します:
docker run --gpus all ubuntu nvidia-smi
nvidia-smiの出力に、マシンに接続されたGPUの情報が表示されるはずです。例えば、私たちのセットアップでは以下のように表示されます:
Wed Nov 8 23:25:53 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 Tesla T4 Off | 00000000:00:06.0 Off | 0 |
| N/A 40C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 Tesla T4 Off | 00000000:00:07.0 Off | 0 |
| N/A 39C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Minikubeのセットアップ
MinikubeのGPUサポートはバージョン v1.32.0 以降が必要です。インストールの詳細については Minikubeのインストールドキュメント を参照してください。このチュートリアルでは、最新のMinikubeリリースを以下のコマンドを使用してインストールしました:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
次のステップはGPUを使用してMinikubeクラスターを開始することです。マシンで次のコマンドを実行します:
minikube start --gpus all
上記のコマンドの出力にクラスターが正常に作成されたかどうかが表示されます。
Launchエージェントの開始
新しいクラスターのLaunchエージェントは、wandb launch-agentを直接実行するか、W&Bが管理するhelm chartを使用してデプロイすることで開始できます。
このチュートリアルでは、ホストマシン上でエージェントを直接実行します。
コンテナ外でエージェントを実行することで、ローカルのDockerホストを使用してクラスター用のイメージをビルドすることもできます。
エージェントをローカルで実行するには、デフォルトのKubernetes APIコンテキストがMinikubeクラスターを指していることを確認します。それから以下を実行します:
pip install wandb[launch]
エージェントの依存関係をインストールします。エージェントの認証セットアップには、wandb loginを実行するか、WANDB_API_KEY環境変数を設定します。
エージェントを開始するには、次のコマンドを入力して実行します:
wandb launch-agent -j <max-number-concurrent-jobs> -q <queue-name> -e <queue-entity>
ターミナル内でエージェントがポーリングメッセージを出力し始めるのが確認できます。
おめでとうございます、LaunchエージェントがあなたのLaunchキューをポーリングしています!キューにジョブが追加されると、エージェントがそれを取得し、Minikubeクラスター上で実行をスケジューリングします。
ジョブを起動する
エージェントにジョブを送信しましょう。ターミナルにログインした状態で以下のコマンドを実行して、シンプルな「Hello World」をLaunchします:
wandb launch -d wandb/job_hello_world:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
この方法で任意のジョブやイメージをテストできますが、クラスターがイメージをプルできることを確認してください。追加のガイダンスについてはMinikubeのドキュメントを参照してください。また、我々の公開ジョブの一つをテストすることもできます。
(オプション) モデルとデータのキャッシング(NFSを使用)
MLワークロードの場合、複数のジョブが同じデータにアクセスすることが望ましい場合があります。例えば、大容量のデータセットやモデルのウェイトを繰り返しダウンロードするのを避けるために、共有キャッシュを持つことが考えられます。Kubernetesは永続ボリュームと永続ボリューム要求をサポートしています。永続ボリュームはKubernetesワークロードにvolumeMountsを作成するために使用され、共有キャッシュへの直接的なファイルシステムアクセスを提供します。
このステップでは、モデルウェイトの共有キャッシュとして使用できるネットワークファイルシステム(NFS)サーバーをセットアップします。最初のステップはNFSのインストールと設定です。このプロセスはオペレーティングシステムによって異なります。我々のVMはUbuntuを実行しているため、nfs-kernel-serverをインストールし、/srv/nfs/kubedataにエクスポートを設定しました:
sudo apt-get install nfs-kernel-server
sudo mkdir -p /srv/nfs/kubedata
sudo chown nobody:nogroup /srv/nfs/kubedata
sudo sh -c 'echo "/srv/nfs/kubedata *(rw,sync,no_subtree_check,no_root_squash,no_all_squash,insecure)" >> /etc/exports'
sudo exportfs -ra
sudo systemctl restart nfs-kernel-server
ホストファイルシステムのサーバーのエクスポート位置とNFSサーバーのローカルIPアドレス、すなわちホストマシンの情報をメモしておいてください。次のステップでこれらの情報を使用します。
次に、このNFSの永続ボリュームと永続ボリューム要求を作成する必要があります。永続ボリュームは非常にカスタマイズ可能ですが、簡潔にするためにここではシンプルな設定を使用します。
下記のyamlをnfs-persistent-volume.yamlというファイルにコピーし、希望するボリューム容量と要求を入力してください。PersistentVolume.spec.capcity.storage フィールドは基礎となるボリュームの最大サイズを制御します。PersistentVolumeClaim.spec.resources.requests.storage は特定の要求に割り当てるボリューム容量を制限するために使用できます。今回のユースケースでは、これらの値を同じにするのが理にかなっています。
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 100Gi # 希望する容量を設定してください。
accessModes:
- ReadWriteMany
nfs:
server: <your-nfs-server-ip> # TODO: ここを入力してください
path: '/srv/nfs/kubedata' # またはお好みのパス
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi # 希望する容量を設定してください。
storageClassName: ''
volumeName: nfs-pv
クラスターで次のコマンドを実行してリソースを作成します:
kubectl apply -f nfs-persistent-volume.yaml
Runをこのキャッシュで利用できるようにするには、Launch queue configにvolumesとvolumeMountsを追加する必要があります。Launch設定を編集するには、もう一度wandb.ai/launch(または\<your-wandb-url>/launch図でwandb serverを使用するユーザーの場合)に戻り、キューを検索して、キューページに移動してからEdit configタブをクリックします。もとの設定は次のように変更できます:
- YAML
- JSON
spec:
template:
spec:
containers:
- image: ${image_uri}
resources:
limits:
cpu: 4
memory: 12Gi
nvidia.com/gpu: "{{gpus}}"
volumeMounts:
- name: nfs-storage
mountPath: /root/.cache
restartPolicy: Never
volumes:
- name: nfs-storage
persistentVolumeClaim:
claimName: nfs-pvc
backoffLimit: 0
{
"spec": {
"template": {
"spec": {
"containers": [
{
"image": "${image_uri}",
"resources": {
"limits": {
"cpu": 4,
"memory": "12Gi",
"nvidia.com/gpu": "{{gpus}}"
},
"volumeMounts": [
{
"name": "nfs-storage",
"mountPath": "/root/.cache"
}
]
}
}
],
"restartPolicy": "Never",
"volumes": [
{
"name": "nfs-storage",
"persistentVolumeClaim": {
"claimName": "nfs-pvc"
}
}
]
}
},
"backoffLimit": 0
}
}
これで、私たちのNFSはコンテナ実行中のジョブで/root/.cacheにマウントされます。マウントパスは、コンテナがroot以外のユーザーとして実行される場合には調整が必要です。HuggingfaceのライブラリとW&B Artifactsはどちらもデフォルトで$HOME/.cache/を使用するため、ダウンロードは一度だけ行われるでしょう。
Stable Diffusionで遊ぶ
新しいシステムをテストするために、Stable Diffusionのインファレンスパラメータを実験します。 デフォルトのプロンプトと合理的なパラメータでシンプルなStable Diffusionのインファレンスジョブを実行するには、次のコマンドを実行します:
wandb launch -d wandb/job_stable_diffusion_inference:main -p <target-wandb-project> -q <your-queue-name> -e <your-queue-entity>
上記のコマンドはwandb/job_stable_diffusion_inference:mainのコンテナイメージをキューに送信します。
エージェントがジョブを取得し、クラスターで実行をスケジュールした後、接続状況に応じてイメージのプルに時間がかかる場合があります。
キューのページ(wandb.ai/launchまたは\<your-wandb-url>/launch図でwandb serverを使用するユーザーの場合)でジョブのステータスを確認できます。
Runが終了すると、指定したプロジェクトにジョブアーティファクトが生成されます。
プロジェクトのジョブページ(<project-url>/jobs)でジョブアーティファクトを確認できます。デフォルトの名前はjob-wandb_job_stable_diffusion_inferenceですが、ジョブページで名前をクリックして鉛筆アイコンをクリックすることで、好きなように変更できます。
このジョブを使用してクラスタ上でさらにStable Diffusionのインファレンスを実行できます! ジョブページから、右上のLaunchボタンをクリックして新しいインファレンスジョブを設定し、そのキューに送信できます。ジョブ設定ページには、元のRunのパラメータが事前入力されますが、LaunchドロワーのOverridesセクションでそれらの値を変更することができます。